2022年の振り返り
アウトプット
デベロッパーズサミット2022にyoutuberとして登壇
「オーバーエンジニアリングって何!?ぶくぶく膨れ上がる仕様、使われない機能、過剰品質、、、突き詰めたら、その先に真のチームの姿があった。」というタイトルで登壇させていただきました。勝手にyoutubeで再演しているのでおいておきます。
ブログ版 i2key.hateblo.jp
また、公募賞(平均満足度1位)を頂きました。ありがとうございました。 codezine.jp
毎年やっている新人向け研修資料公開
毎年新人向けにやっている研修資料の2022年度版です。つぎたしつぎたしで毎年アップデートしております。
ブログ2本
アドベントカレンダーシーズンにしかブログを書かなくなってしまった・・・・・。のですが、結構ブクマやPV数がありまして、ありがとうございます。
「納期コミットのオーダーは結果的に納期を遅らせること」を逆手にとる i2key.hateblo.jp
現実世界は動的なのに静的に解こうとしている危うさのようなものへの自戒 i2key.hateblo.jp
youtube活動
システム開発に関連する単語を勝手に定義していく活動を地道にやっております。教科書のように演繹的に、、、ではなくどちらかというと帰納法的に経験と実態から定義しております。勝手に。
プロジェクトって何?
プログラムマネジメントって何?
(原著巡り)人月の神話って何?
都市伝説を探る「ウォーターフォールの何が誤解なのか!?」(原著巡りシリーズ)
スクラム(アジャイル)の起源:The New New Prodct Development Game
プロスペクト理論からソフトウェア開発を考える
「不確実性」ってなんだ?
「体制」ってなんだ?
「優先順位」ってなんだ?
プログラミング言語は言語なのか?
シンプルとは?複雑とは?KISSの原則
要件定義の理解をアップデートする
続・要件定義の理解をアップデートする
リスクって何なんだ?
買ってよかったもの
今年買って良かったもの。バブアーオーバーサイズビデイル、パタゴニアレトロX、トライアンフボンネビルt120、ランドローバーディフェンダー90。あと、大型バイクの免許。
今年買って良かったもの。バブアーオーバーサイズビデイル、パタゴニアレトロX、トライアンフボンネビルt120、ランドローバーディフェンダー90。オタク中年の散財。#newdefender #defender #barbour #triumph #bonneville pic.twitter.com/xp6Kg1yXEU
— Itsuki KURODA (@i2key) 2022年12月31日
現実世界は動的なのに静的に解こうとしている危うさのようなものへの自戒
Recruit Engineers Advent Calendar 2022 - Adventar 23日の記事になります。
1. 方法論は限定スコープ内における合理性の話である
書籍などで得られる概念や方法論(技術含む)は、その書籍がスコープとしている中での限定合理性の話をしており、 書籍がスコープとした範囲における論理的正しさである場合がある。
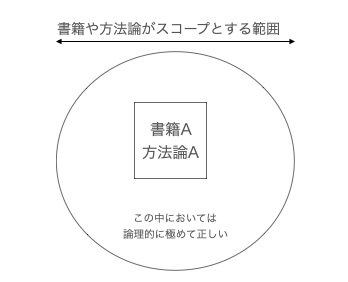
特定のスコープの中においての最適なので、実は全体からみると個別最適だったりする。 つまり、実は引いてみると非効率なことを近距離でみると効率的だと主張している場合もある。
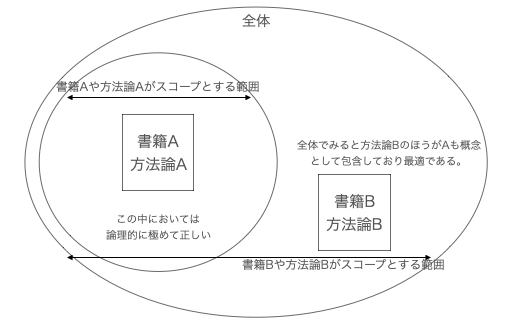
この包含関係による概念的強さみたいなものは存在しており、例えば、制約条件理論みたいなものは、様々な概念の上位に存在しており包含していたりする(そう勝手に思っている)。スコープを決めそのスコープ内におけるボトルネックを活用しスループットを最大化させるという概念的な強さはあり、その切り口で理解するとアジャイル系のプラクティスみたいなものはそのサブセットのように見えたりする。リアルオプション戦略も同じような概念的強さの感覚はある。プログラムマネジメントみたいなものも同様の強さを感じる。
2. 現実世界は動的なのに静的に表現されがちであることを認知する
また、書籍の特性として、現実世界では動的なものを静的に扱われやすい傾向はある。 それはありとあらゆるコンテキストに対応することは出来ないため仕方がない。
リーンスタートアップやアジャイル関連の書籍・方法論における
「仮説検証は小さくやるべきである。」
この「小さく」とはどのくらいなのか。
起業して間もないスタートアップの小さく仮説検証と、 1000億円ビジネスを何個も持っている会社の小さく仮説検証における、小さくとは同じなのだろうか。 なにか違う気もする。*1
つまり、実は相対性がそこにありそうである。 時価や相場観のようなものがあり、それに対して小さいかどうかなのかもしれない。 しかし、書籍においてはそんなこと知ったことではないので、 「小さく仮説検証せよ」にしかならない。至って静的である。
本来相対性の話なのに絶対値として理解するように書かれてしまう。
読者自身に相場観がないとここで絶対値的な理解をしてしまい、自分の文脈に合わない利用をしてしまう。
ここでいう相場観とは事業理解のようなものやそれに伴う現場感のようなものかもしれない。
3. 現実世界は動的なのに静的に解かれがちであることを認知する
文脈に則さないマイクロサービスを構築してしまうようなケースしかり、将来発生するかもしれない「もしかしたら」を過大評価し備えすぎるみたいなのも似ているかもしれない。 本来、「悪いことの発生する確率 x インパクト」の期待値で見るべき話であるが、相場観がないと、1%程度しか発生しないことを100%発生すると思い込んでしまう。 しかし、書籍で得られる方法論は、前提として100%発生する側の視点で書かれていることもある。それは前述の図の通り、その問題が発生した状況を解決するための方法論であれば、その世界においては正しい。しかし、現実世界ではその状況になるかどうかは場合による。
本質的には事象を期待値で理解し適切にリスクを取れるエンジニアリングをすべきであり、それをしないとリスクゼロに向かう投資サチュレーションオリンピックが始まってしまう。リスクゼロにするまで無限の投資が始まるし、無限のエラーハンドリング処理が書かれるかもしれない。または、無限のテスト項目を消化しなければならないかもしれない。バグが0であることを証明しなければならないかもしれない。

しかし、教科書知識だけなどで現場感がないと、そもそも確率とインパクトが見えないからリスクもとれないし、ほとんど発生しないことを絶対発生すると思い込んでしまうし、ちょっとしたことも、一大事だと思ってしまう。
つまり、方法論というものは、それが成立する前提がかならずあり、そこでスコープが定義され、そのスコープ範囲内において、限定合理性を追求するものである。と理解をするとよい。これが、それらとの良い付き合い方なのではなかろうか。
また、その前提においても、他の存在可能世界の存在可能性があることを知っていることも重要である。 自分は1つの存在可能世界にいるだけであり、他の可能性の世界も並列で存在しているし、その世界毎に時価や相場感はあり、異なるのである。 このブログ自体も私が向き合っている1つの世界の相場観に過ぎなかったりもする。
という、方法論に対するスタンスの話。
4. 問題引き寄せバイアスを認知する
また、方法論に対する以下のようなバイアスが生まれがちであり、気をつける必要がある。
自分の理解力の範囲内(得意領域・関心領域)に問題を引き寄せることがある。
局所的な世界においては論理的に正しいが全体でみると最適ではないというパターンである。
・生産性が悪いのは・・・技術が古いからである。だから新技術にすべきである。
・生産性が悪いのは・・・デプロイ回数が少ないからである。デプロイ回数を増やすのである。
・生産性が悪いのは・・・開発開始からリリースまでのリードタイムが長いからである。リードタイムを最短にするのである。
・生産性が悪いのは・・・ウォーターフォールだからである。だからアジャイルにすべきである。
それは、ホントだろうか?生産性が悪い他の要因は考えた?極端な例をあげるなら、そもそも作るべきものを間違っていた。とか、想定する顧客は存在していなかったとか。そういう話もあるかもしれない。要因として。
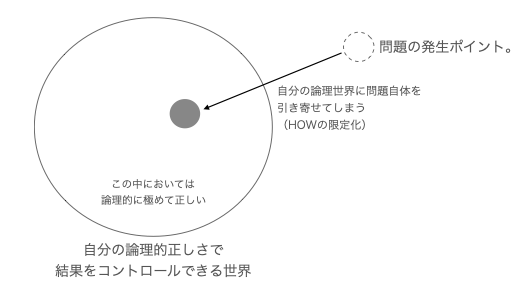
しかし、教科書に感化されている状況だとこれに陥りやすい。 知っている方法論に問題を引き寄せ、それに当てはめて解こうとする。 局所的には正しく見えるが、本質的には最適ではない。 自分で解ける論理領域への問題引き寄せはオーバーエンジニアリングを生む。
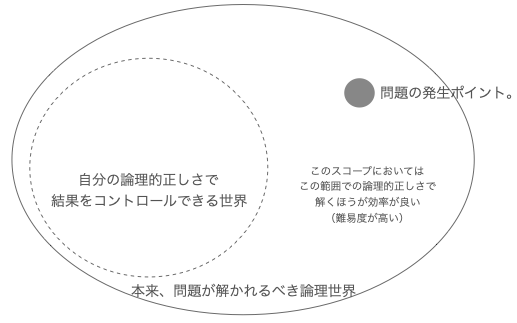
問題の発生ポイントの適切なスコープにおいて、そのスコープにおける最適な方法論にて解くべきである。
5. まとめ
・現実世界は動的であるが静的に解こうとしていることがある。
・動的に捉えるには、ある種の相場観(=現場感)のようなものが必要である。
・現実世界の相場観がないと「もしかしたら(確率1%)」が「絶対(確率100%)」になってしまう。
・現実世界の相場観がないと「ちょっとだけ(インパクト小)」が「重大(インパクト大)」になってしまう。
・無意識的に自分の理解力の範囲内(得意領域・関心領域)に問題を引き寄せることがある。
・本来解くべきスコープで問題に対峙していない場合、局所的には正しく見えるが本質的に最適ではない解決になる。
何か問題に遭遇したときに、ああ、これはあのパターンのやつだ!となる自分がおり、そのときは問題を自分の既知のHOWに引き寄せてしまっているときがある。
だから、自戒もこめて・・・・。というブログでした。
関連しそうなテーマをyoutubeで勝手に定義して解説しています
youtu.be
*1:スティーブブランクも Steve Blank Is the Lean Startup Dead? にて以下のように言っている。
When capital for startups is readily available at scale, it makes more sense to go big, fast and make mistakes than it does to search for product/market fit. The amount of customer discovery and product-market fit you need to do is inversely proportional to the amount and availability of risk capital.
「納期コミットのオーダーは結果的に納期を遅らせること」を逆手にとる
これは Recruit Engineers Advent Calendar 2022 - Adventarの13日のエントリーです。(書いているのは21日です。)
1. 納期コミットのオーダーは結果的に納期を遅らせる
先日、興味深いエントリーを読んだ。
これにつてはほぼ同じようなことを社内のtimesチャネルでも会話しており、スケジュールへの向き合い方についてメタ的理解に昇華させたい。
我々が納期をコミットしなさい、確実に守れる日を教えてと言われたときにやることは、、、
確実に納期を守れるように、余裕をみる。である。
------------------------------------------------------------
■:実作業日(問題なければできそうな工数)
□:バッファ日(例えば50%の確率で問題おきたときに使う予備日。数字てきとー。)
設計工程 ■■■■■■■■□□□□ (■:8日、■+□:12日)
実装工程 ■■■■■■■■□□□□ (■:8日、■+□:12日)
試験工程 ■■■■■■■■□□□□ (■:8日、■+□:12日)
合計
■■■■■■■■□□□□■■■■■■■■□□□□■■■■■■■■□□□□(■:24日、■+□:36日)
------------------------------------------------------------
36日後にリリースできます。とコミットする。(便宜上、土日ぬいてるよ)
仮に予定よりも前倒しにおわったとはいえ、バッファがあるから、「念の為」「不安だし」「より良いものを」という理由でバッファは善の活動により費消される傾向がある。リリース直前のバッファが余った状況であれば、誰しもが「念の為」強化試験をしたくなる。そういうもの。つまり、使わないという手はない。それが大規模開発になればなるほど。別に悪だとはいっていない、そういうもの。人間だもの。(参考:パーキンソンの法則)
------------------------------------------------------------
※ また、以下のようなCCPMバッファ的な話はそれについて言及したいわけではないので今回はスコープアウトする。
■■■■■■■■■■■■■■■■■■■■■■■■□□□□□□□□□□□□
------------------------------------------------------------
このとき、ポイントとしては、納期コミットのオーダーを出したひとは、実は、自ら納期を遅延させたということに気づいていないケースがある。というか、99%が気付いていない。営業広報とかが現場オペレーションとして走るため日にちを確定させたいような場合は、確定させることが大事なのでよいのである(日付により他のオペレーションと同期をとることが要件であると認識する)が、例えば、早ければ早いほどよいもの。リリースと同時に事業実利がリアルに積み上がるようなものの場合、早く出した日数分だけ、実利が多く積み上がる。
2. 納期コミットのオーダーは結果的に納期を遅らせることを逆手にとる
そのため、思考実験。
□が混入している理由は、納期を確定させるために見積もりという行為をしたから。早ければ早いほど良い場合は、逆に考えると、実は、(コミットのための)見積もりをしない。(コミットのための)納期を確定させない。ただし、成功確率は50%(数字てきとう)。というギャンブルをやるかどうかという捌きが前段にあってもよいのかもしれない。自分たちの作業精度を上げるための自分たちのための見積もりはそれはするとして。また、事業KPIにコミットしているモチベーションの高いチームであることは大前提である。
納期確定で動くなら、36日後にリリースできます。確実に。
------------------------------------------------------------
■■■■■■■■□□□□■■■■■■■■□□□□■■■■■■■■□□□□(■:24日、■+□:36日)
------------------------------------------------------------
納期未確定で成功確率50%でよければ、24日後にリリースできます。多分。失敗したら、36日〜へたしたら40日くらいかかるかもね。このギャンブルのる?のらない?
------------------------------------------------------------
■■■■■■■■■■■■■■■■■■■■■■■■(■:24日)
------------------------------------------------------------
事業実利の期待値をみて、その積分値を最大化するための、ギャンブル。(=プログラムマネジメント的思考)
遅延リスクバッファをすべて削り、それを時間短縮可能性に変換している。
3. 納期という日付すらも実はビジネス要件なのである
つまり、約束すると遅くなるというメカニズムを前提とした上で、約束する(日付の確定)をビジネス要件とするか、約束しない(リリース速度)をビジネス要件とするか。これすらも要件として扱うことが大事である。これによって開発プロセス自体もビジネス要件にあわせて変化することになる。(例えばウォーターフォールと言われているタイプから、一個流し的なカンバン方式へ変化したり。締め切りにフォーカスではなく、優先順位にフォーカスしていくことになる。積み上がるKPIの総量が最大化するには、バッファを詰んで日付を確定させることが最も効くのか、日付を確定させず(ゆるく決めるだけ)に遅延リスクを飲むほうが効くのか。)
今まで前提としてしまっていた納期というもの自体もビジネス要件と捉え、他のバックログ的なリストに混ぜ込むイメージである。納期がビジネス上最も重要度が高いのであれば、それに対して遅延リスクバッファをたくさん積むべきであり、そのバッファ分の原資になるリソースは例えばチームのキャパシティから割り当てられることになる。これが意味することは、その開発サイクルにおいて、同時に開発出来る案件は減ることを意味する。特定の案件の日付を確定させることがビジネス上、最重要なのであれば、他の案件は優先度が下がるはずである。
イメージで補足すると以下のようになる。最も事業実利が積み上がるように開発をするべきである。納期を約束するかどうかはそのための手段の1つである。
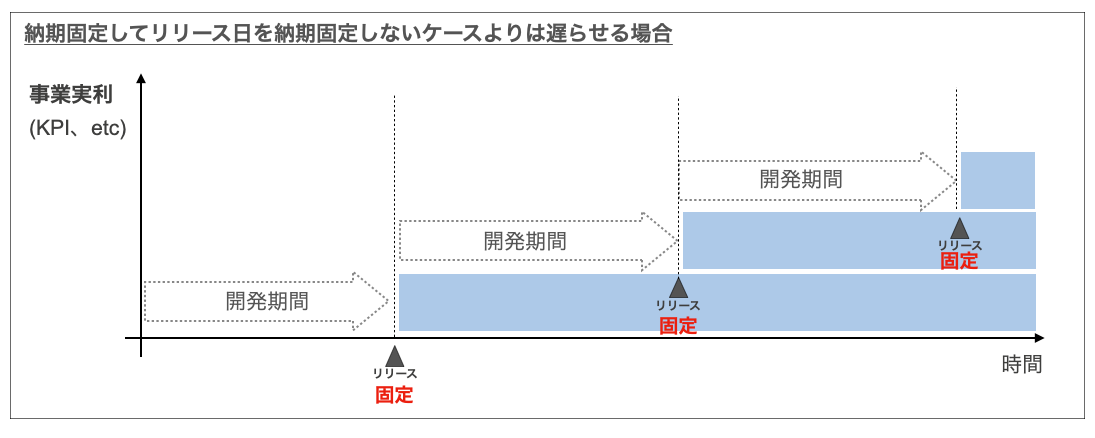

また、付け加えると、「見積もりは予測であり約束ではないのである」とか正しい理屈を説いても基本的に意味がなくて、期日守るからリリース日遅くなる or 期日なしでリリース日早まるけど確度80%、のようなトレードオフの形にして選択可能な状態にすることが重要である。レバーとして実装できればあとは選ぶだけであり、「見積もりは〜予測で〜」のような開発の正義みたいなものを説いて理解していただくような労力すら必要なくなる。
おまけ. 小難しい理屈は「全員が」理解している必要はない
合わせて、フロー効率やリソース効率みたいな開発としての正義のようなものも同様である。そういう小難しい理屈を関係者全員が理解している必要はなく、その考え方が染み込んで浸透した状態の選択肢をいくつか用意出来れば良い。結果的にフロー効率がよくなる構造 or リソース効率が良くなる構造を作れれば良いわけで、何を捨てて何を取るかという状態になっていることが実行性が高い状態である。しかしながら、なぜか、小難しい理屈を我々は説明したくなってしまうのである。合気道すべきところを何故か正拳突きをしてしまうのである。そんなこと知らなくても良いのに。
思想みたいなものはあえて声高に説明するのではなく構造の中にそっと織り込んでなじませておけば良くて、そうすれば無意識下におかれ自然とスケールする。思想を理解しないと適用できないみたいな状態だと理解出来る人にしかスケールしないため効率が悪いのである。しかし、、、、、、方法論者は、その小難しい理論が如何に正しいか・素晴らしいかを説明してしまうのである。という自戒を込めて。
2021年振り返り
サマリ
- 体重が100kg から 79kgに減量成功。目標BMI値の人と同じ食事を取り続けるとそこにBMIは収束するらしい。
- youtubeはじめた。チャンネル登録よろしくね!!
- バイクを趣味にした。バイク免許を小型自動二輪(8月卒業)、普通自動二輪(10月卒業)、大型自動二輪(12月入校)
- 納車を1年で3回経験し、納車中毒に。納車のUX最高。好きな単語は納車。今年の1年を表す単語は納車。
仕事
1月にRegional Scrum Gathering Tokyo 2021にてカネとAgileという登壇をしました。
5月に新入社員向けの研修資料公開。新人のとき聞きたかったといわれた話を新人向けにしました。
事業価値とエンジニアリング。
会社のアドベントカレンダーに以下を投稿しました。
大事ではないことを大事だと錯覚した結果、オーバーエンジニアリングになる i2key.hateblo.jp
健康
6月に緊急入院。健康診断で血糖値が異常値を叩き出す。食生活の改善と運動を始める。
食事はBMI22の人の食事を朝昼晩徹底することで、I/Oのバランスがとられるところまで収束させていく設計で摂取(開始時BMI30)。目標BMI値の人の食事をとっているとそこに収束するらしい。半信半疑であったが。とりあえず、栄養士に言われたとおり食品群は全てをバランスよく食べることを徹底。1日1900kcal。米は1日160g×3。魚類1日120g。肉類1日90g。卵1日50g、大豆豆腐系1日200g。乳製品1日180g。野菜1日360g。油脂類1日20g。塩分は1食2g。などなど。運動は食後の血糖値上昇を緩和させるために食後15分後に30分実施。また、会議中もひたすら自転車をこぐことを徹底。fitboxを購入。テレワークに最適。
家にfitbox 届いたらしい。 pic.twitter.com/Q8nrzTV8HD
— Itsuki KURODA (@i2key) July 1, 2021
労働環境に運動を取り込んだ。 pic.twitter.com/oSBOB591EE
— Itsuki KURODA (@i2key) July 2, 2021
結果的に、BMI22の人の食事を取り続けて、ひたすら自転車こいでいたら、本当にBMI30→BMI22まで減った。今食べているものから何かを削るという思考ではなく、目標のBMIの人の食べている食事を取り続けるほうがゴールからプルしている状態になり、理に適っているという知見を得た。そして、20キロの脂肪を纏っていた体から卒業し、冬が寒いということを知った。
youtube
友人とyoutubeはじめました。プロダクト開発をしていると良く聞いたり使う言葉。でも、よく考えると意味が分からない。そんな言葉を、自分たちで勝手に定義してみようとはじめました。 あくまで、勝手に定義しているだけなので、本当に正しい定義かどうかは分かりません。でも、定義する途中でプロダクト開発の奥深さや楽しさを少しでも共有できたらなと思っております。
オーバーエンジニアリングついて。
PIMBOK第7版について
技術的負債について
システムってなんだ?
生産性とは
俺のプロダクト開発用語辞典 www.youtube.com
車
1月に人生初の車購入。見に行って翌日契約。BMW MINI F56 cooper。かわいい。おしゃれ。なお、運転の感覚がゴーカートフィーリングと言われているらしいが、そのフィーリングを感じるほどの感度はもっていない。
バイク
趣味が海外旅行(30カ国以上行っている)とゲームだったため、海外旅行がコロナで封じられ外に出る理由がなくなってしまった。なんとなく見ていたTOKYO BB / TOKYO BB returnsというyoutubeに触発されバイク買ってみようかなと。強制的に外出することになる趣味を作るのよいかもなーと。で、なんか、今ハンターカブってのが流行っているらしい。youtubeでいろんな芸能人がこぞって買い始めているようだ。ということで、7月、免許取得前にHONDA ハンターカブ購入(youtubeが購買活動へ作用するというマーケ効果を肌で感じた)。8月に二日間で小型自動二輪(AT)教習&免許取得。排気量125cc。
試しに秩父にいってみたところ、公道60km/hでエンジンが悲鳴を上げており、更には秩父の山の坂道も相当キツく、排気量に物足りなさを最初のツーリングで味わい翌日には普通自動二輪(MT)の教習所に入校。排気量400cc。
9月(普通自動二輪の免許取得前に)BMW G310GS購入。10月にハンターカブ売却(ほぼ買値で売れた)。普通自動二輪(MT)教習。免許取得。排気量400ccにランクアップ。11月、BMW G310GS納車。
これで、高速道路にのれる。ということで、高速道路走行をしてみたら、80km/h巡航はまったく問題ないのだけど、それ以上の速度になるとエンジンが悲鳴を上げ始める。エンジンが頑張ってる感すごく出てくる。なんかすごく心理的なストレスがかかる。ということで、帰宅後に大型自動二輪(MT)教習所入校。2022年1月から教習開始。
一年で納車を3回やってると納車中毒みたいになる。好きな単語は納車。好きなUXは納車。引き続き来年も納車していくために頑張っていきたい。
大事ではないことを大事だと錯覚した結果、オーバーエンジニアリングになる
本ブログは Recruit Advent Calendar 2021 - Adventarの25日の記事になります。
ITビジネスやサービスにおけるプロダクト開発で良くある、作りすぎ。やりすぎ。
無駄なく、効率的にと思っても、ついつい発生しちゃう。
こういうの、オーバーエンジニアリングって言うらしいよ!?
でも、どこからオーバーで、どこまではオーバーじゃないんだ!!
ということで、勝手にオーバーエンジニアリングを定義してみようと思います。
作り過ぎて、時間や金を無駄にすること????
とっかかりとして・・・まずは一般用語としてのオーバーエンジニアリングの意味をwikiで調べてみると以下のように記述されています。
wikipedia(英語版) Overengineering - Wikipedia 一部抜粋。
Overengineering (or over-engineering,[1] or over-kill) is the act of designing a product or providing a solution to a problem in an overly complicated manner, where a simpler solution can be demonstrated to exist with the same efficiency and effectiveness as that of the original design.[2] Overengineering differs from Planned Obsolescence which seeks to alter a design to produce an artificial limit on a product's lifespan or otherwise make it unfashionable. Overengineering is often identified with design changes that increase a factor of safety, add functionality, or overcome perceived design flaws that most users would accept. Overengineering can be desirable when safety or performance is critical (e.g. in aerospace vehicles and luxury road vehicles), or when extremely broad functionality is required (e.g. diagnostic and medical tools, power users of products), but it is generally criticized in terms of value engineering as wasteful of resources such as materials, time and money.
wikipedia(英語版) → DeepL
オーバーエンジニアリング(またはオーバーエンジニアリング[1]、オーバーキル)とは、製品を設計したり、問題の解決策を提供したりする際に、元の設計と同等の効率や効果を持つ、よりシンプルな解決策が存在することを証明できるのにもかかわらず、過度に複雑な方法で設計することである[2]。 オーバーエンジニアリングは、製品の寿命を人為的に制限したり、流行遅れにしたりするために設計を変更しようとする計画的陳腐化とは異なります。オーバーエンジニアリングは、安全率を高めたり、機能を追加したり、ほとんどのユーザーが受け入れるであろう設計上の欠陥を克服するような設計変更と同一視されることが多い。 オーバーエンジニアリングは、安全性や性能が極めて重要な場合(航空宇宙用車両や高級ロードカーなど)や、極めて広範な機能性が要求される場合(診断ツールや医療機器、製品のパワーユーザーなど)には望ましいが、バリューエンジニアリングの観点からは、材料や時間、お金などの資源を無駄にしていると一般的に批判されている。
大事そうなものを赤字にしましたが、つまりは、やりすぎてしまった結果、リソースや時間、お金などの資源を無駄にしているって読み取れます。 また、青字の部分は、逆に性能オリンピックになっても問題ないというか逆にそれが望ましいケースもあるよ。といってます。 とはいえ、私が携わっているITビジネスにおいては、どちらかというと赤字側の文脈が強いですが、全体的には良いことなのか悪いことなのかよくわからないですね。
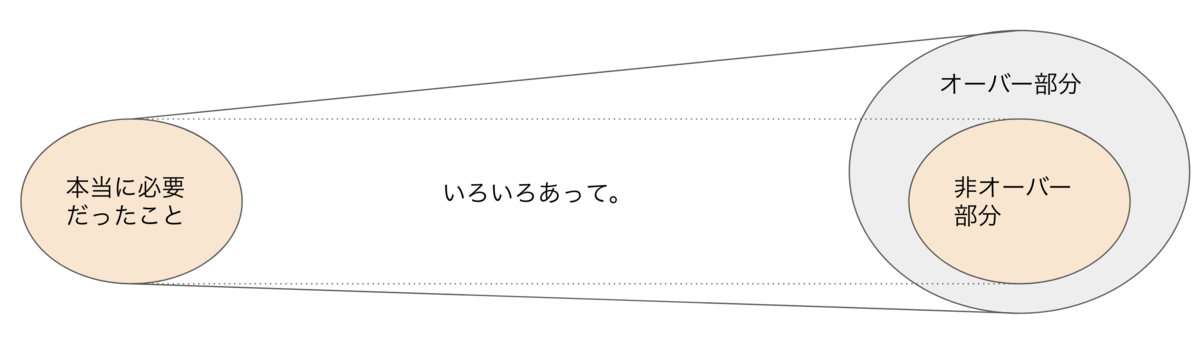
ただ、どうやら本当に必要だったものに対して、なにかオーバーなやりすぎが発生してしまい、全体として当初想定していたものよりはブクブク膨れ上がる感じ。 そんなイメージ。
いろいろなことがあって膨れ上がる
膨れ上がるといっても、いきなりドカンと倍になるとかそういう話ではない気がしていて、徐々に・・・、何かいろいろなことがあって、本当に必要だったものよりも大きくなってしまうんだろうなと。 こんなイメージです。
いろいろなことがあるんだけど、そのいろいろなことが発生するタイミングはシステム開発のケースでいうと各開発工程において発生している気がする。なお、多くのことをまとめて一括でやるようなウォーターフォールと言われているようなケースや小さく1つずつクルクル回してやっていくアジャイルと言われているようなケース、いろいろあると思うけど、一般的にV字の工程はどれもやることは同じであるため、便宜上ひとくくりにして表現しています。

では、いろいろなことがある、色々ってなんだろう?を列挙してみる。あくまで全てではないけど、開発の現場にいるとよく遭遇しそうなあれこれ。

例えば・・・・・
- 要求定義
存在しないユーザを想定して、仕様を増やしちゃう。そもそもそんなユーザーはいないかもしれないのに、脳内に存在する実在しないペルソナに対して仕様を増やしにいってしまう。
- 要件定義
大事な気がする仕様が問題になって、更なる解決が必要になっちゃう
- 設計
将来に備えようとして、備え過ぎちゃう。拡張性とか柔軟性とかを過度に必要だと思い盛り込んでしまう。備えること自体は良いのだけど、、、、備え過ぎてしまう。
必要以上のレビューや文書化といったプロセスを行ってしまう。誰が見るんだっけ?それ今後も使うんだっけ?みたいな。
- コード
全体の性能ネックではないところが、大事な気がして高性能にしちゃう。別にそこシステム全体からみたらボトルネックじゃなくない?とか。
- テスト
直さなくて良いバグを直しちゃう。リスクに対する考え方や事業のコンテキストにもよるけど、目についたバグを全て確実になおしてしまう。とか。
大事だと錯覚してしまう
もういちだん、解像度を高めるために要件定義を例に深ぼってみます。
大事な気がする仕様が問題になって、更なる解決が必要になっちゃう の深堀り

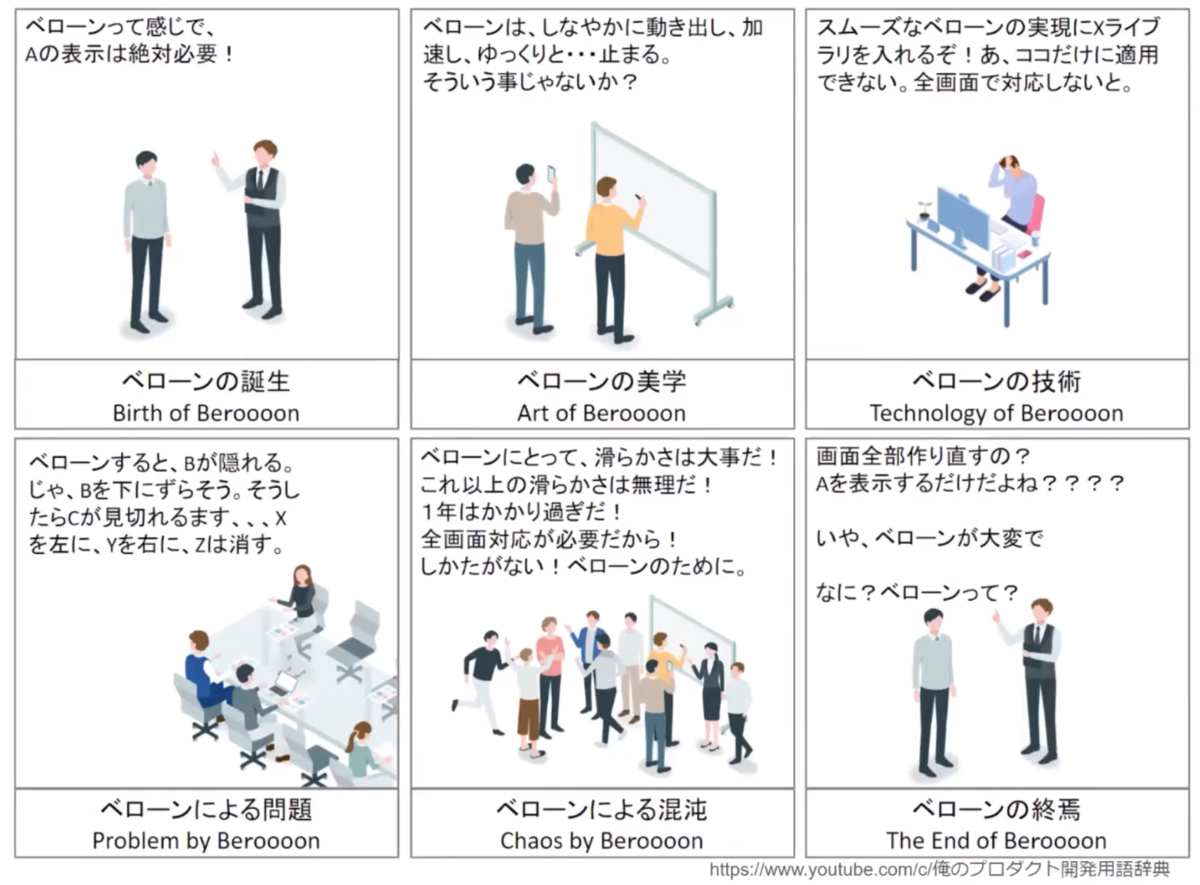
例えば、「ボタンAを押したらベローンとなる。」という要求があったとして、、、このときの要件は「(システムは)ボタンAが押されたらベローンとする。」と定義されたとする。ただ、このときにベローンとするとボタンBが隠れてしまうという問題が起きる。こういうことありますよね。要件を実現するのに障壁となる問題が発生するケース。現実世界では、こんなベローンとしたら隠れちゃいましたーみたいなしょぼい話ではないと思うのだけど、あくまでわかりやすくという意味での極端な話として。
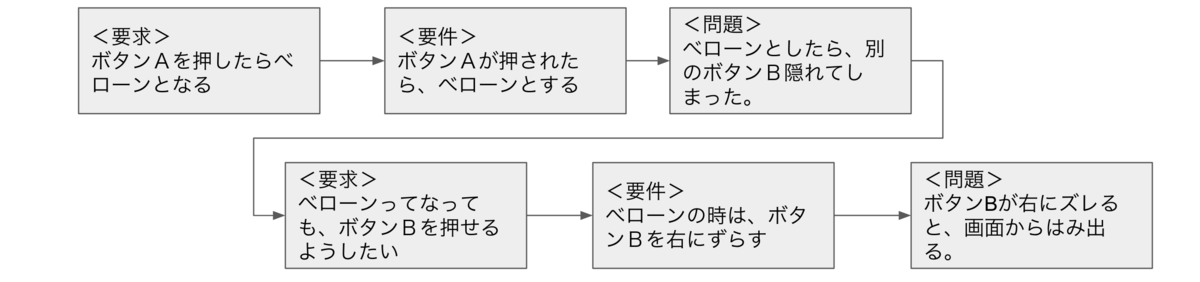
こうなると要件実現のためにこの問題を解決しないといけない。ということで新たな要求がここで発生する。「ベローンってなってもボタンBを押せるようにしたい」って。これがすごく現場で発生してる気がする。で、その新たら要求に対して、新たな要件がうまれる。「ベローンのときはボタンBを右へずらす」。そして、ベローンのときにボタンBを右にずらすと・・・・・「ボタンBが画面からはみでちゃう」という新たな問題が発生・・・・。
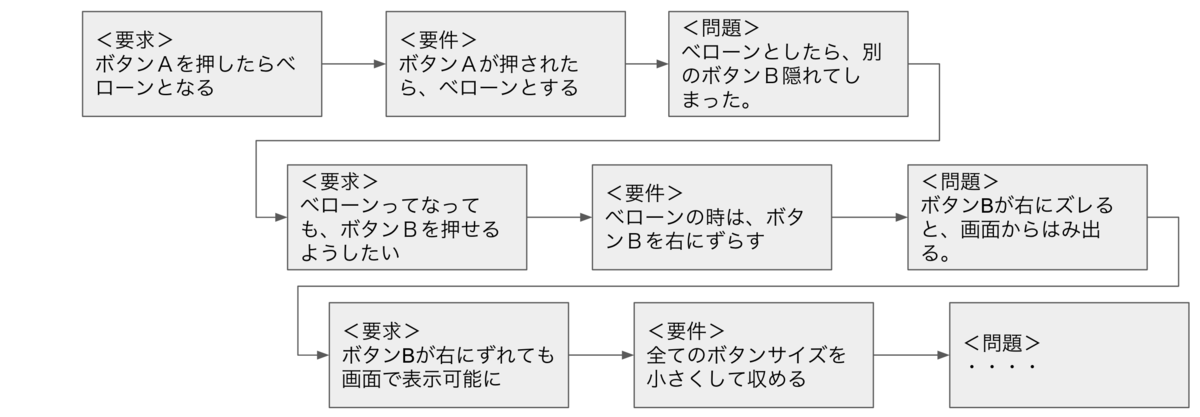
同じようにこの地獄の構造は続いていく・・・・。何かを作ろうとしたら、それを作るために何か問題が発生して、それを解決するために新しい要求が生まれて・・・・の連鎖。もりもりやることが膨れ上がっていく。やりすぎてる感ある。
これを発生させないためにはどうすればよかったのだろうか???
「ボタンAを押したらベローンとなる。」という要求定義の時点で、「ただし、ボタンBは隠れないようにする。」とまで定義しなければならなかったのか。しかし、そうなると、起こりうる問題を事前に全て想定しきらないとならないというなかなかの無理ゲー感がでてくる。ベローンくらいなら想定可能だと思うけど、実際は、影響範囲を全て把握した上での最強の要求定義要件定義をすることになるのは、あまり現実的ではない気もする。
では、これはなるべくしてなるオーバーエンジニアリングなのだろうか・・・・。
そうではない気がする。 そもそも要求に立ち返って考えたときに、「ボタンAを押したらベローンとなる」は、本当にベローンとしたかったのか。何かの得たい情報がベローンと表示されていればよかったのかもしれない。仮に「ボタンAを押したら画面上にホニャララって情報が表示される」みたいな要求であれば、この問題は起きなかったのかもしれない。要求の段階で「ベローン」(HOW)を指定してしまったがために、それ以降の工程では、「ベローン」は大事なものに見えてしまい、要求を受けた側はそれをどうしても実現せねば。となってしまっているように見える。要求を出した本人は、なんとなく「ホニャララ情報をさ、ベローンって感じでもいいから、なんかだしてよ」という温度感であって、ベローンにこだわりはなかったのだけど。みたいな。

これをシャープに言語化すると、要求に手段が混じってしまっているが故に、その手段が重要だと思ってしまった。と言える。
そして、最初の問題以降の淡い青色の部分は全てそんなに重要ではないベローンに向き合ってしまったことになる。そこの問題をどんなに解決してもそもそも重要ではないというか。意味がないというか、、、、つまり、、、、無駄。問題発生時に、要件に対して、「じゃあ、ベローンじゃなくて、ペロンでよくね?」で発生しなかった話であり、ベローンが重要だと錯覚してしまったことが全てのはじまりなのかもしれない。 要求の段階で「ボタンAを押したらベローンとなる。(けど、ベローンは実はそんな重要じゃないです。こだわりも1ミリもありません。)」ってなっていたら「あ、これそんな大事じゃないだwww」ってなりこれは錯覚を防げたのかもしれない。濃淡の話。
つまり、・・・・本来は大事じゃないものを大事だと錯覚した結果、作りすぎて(やりすぎて)、時間や金を無駄にしてしまう。ということなのかもしれない。
無駄は錯覚によってうまれる
上記での錯覚がオーバーエンジニアリングを引き起こしているのでは?という気づきをもとに、前述の各工程毎に出した「いろいろあって」もりもりやることが膨れ上がる例に対して、「ほにゃららだと錯覚してしまう」という表記にしてみると・・・・。
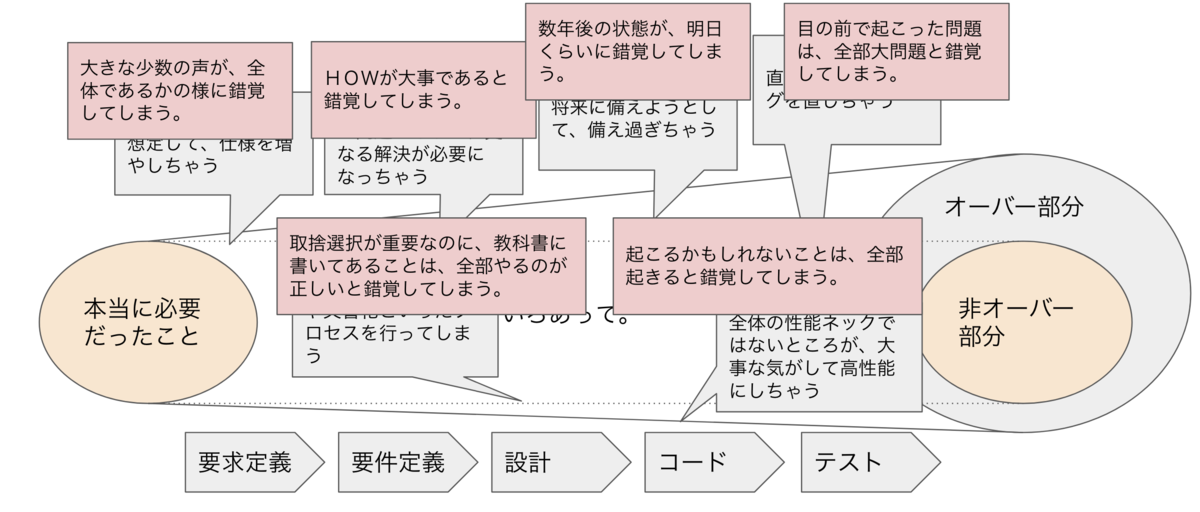
- 要求定義
存在しないユーザを想定して、仕様を増やしちゃう。そもそもそんなユーザーはいないかもしれないのに、脳内に存在する実在しないペルソナに対して仕様を増やしにいってしまう。
→ 大きな少数の声が、全体であるかの様に錯覚してしまう。
- 要件定義
大事な気がする仕様が問題になって、更なる解決が必要になっちゃう
→ HOWが大事であると錯覚してしまう。 (さっきのベローン)
- 設計
将来に備えようとして、備え過ぎちゃう。拡張性とか柔軟性とかを過度に必要だと思い盛り込んでしまう。備えること自体は良いのだけど、、、、備え過ぎてしまう。
→ 数年後の状態が、明日くらいに錯覚してしまう。 (5年後には1億ユーザーなんだけど、なぜかそれが明日だと思ってしまった。みたいな。流行ってから悩めばいい系。)
必要以上のレビューや文書化といったプロセスを行ってしまう。誰が見るんだっけ?それ今後も使うんだっけ?みたいな。
→ 取捨選択が重要なのに、教科書に書いてあることは、全部やるのが正しいと錯覚してしまう。 (文脈を意識してない型に当てはめるタイプのやりかただと起こる感じ。目的意識不在のプラクティス全部盛り的な。)
- コード
全体の性能ネックではないところが、大事な気がして高性能にしちゃう。別にそこシステム全体からみたらボトルネックじゃなくない?とか。
→ 起こるかもしれないことは、全部起きると錯覚してしまう。
- テスト
直さなくて良いバグを直しちゃう。リスクに対する考え方や事業のコンテキストにもよるけど、目についたバグを全て確実になおしてしまう。とか。
→ 目の前で起こった問題は、全部大問題と錯覚してしまう。 (冷静になって考えると大した問題じゃないのに目の前でおこるとまあまあバイアス発生するよね。)
まとめ
つまり、オーバーエンジニアリングとは・・・・本来は大事じゃないものを大事だと錯覚した結果、作りすぎて(やりすぎて)、時間や金を無駄にしてしまう。ということであり、それを引き起こすトリガーとなる錯覚は例えば以下のようなものがある。と言えそうである。
- 要求にHOWが入ってる(HOWが大事であると錯覚してしまう)
- 少数ユーザの意見(少数の意見が、全体の意見であると錯覚してしまう)
- とてつもなくグロースするサービス(数年後の状態が、明日のことのように錯覚してしまう)
- リスクを取らない(目の前で起きた問題が、すべて大問題であると錯覚してしまう)
- リスクを取らない(起きるかもしれないことは、大抵起きると錯覚してしまう)
- 教科書をなぞる(取捨選択こそが大事なのに、全部やらないとダメだと錯覚してしまう)
という、勝手にオーバーエンジニアリングを定義してみた!でした。
余談
開発における文脈と時間軸を正しく理解していないと、錯覚によりオーバーエンジニアリングが発生する。
全ての可能性が全て発生した世界が多分オーバーエンジニアリングの理論上最大拡張幅。前述の図のブクブク膨れ上がったやつ。
つまり、リスクテイクできていない世界。
例えば、この機能は事業的に致命的ではないためバグってもよくない?がいえると縮小する。
このプロダクトが流行ってから悩めばよくない?がいえると縮小する。
このコードは1年に一度くらいしか触った実績ないから、工数かけてまでキレイにしなくてもよくない?がいえると縮小する。1年に1度あるかないかみたいな時間軸が抜け落ちると、目についた汚らわしいものすべてがキレイにする対象になってしまう。無限にお金と時間があるなら良いのだけど、基本的には限られた資源で日々活動をしているため、そんな状況にはなりにくい。
そのためこれらのリスクを取れない、つまり、「事業理解のない提案」になるとどうしてもコストが最大化する。
全部のリスクをヘッジする実装をするから。
リスクをマネジメント対象にすることってこういうことなんだろうな。(感想)
おまけ
このような勝手な定義を毎週youtubeでスライド作りながらしております。
今回のオーバーエンジニアリングついて。
PIMBOK第7版について
技術的負債について
俺のプロダクト開発用語辞典 www.youtube.com
2019年振り返り
2019年皆様たいへんお世話になりました。2019年は会社のほうでは執行役員になり、今までとまた全く違った景色の中であっという間に年末を迎えることになりました。そのため、振り返ってみると登壇2本しか社外へのアウトプットはしておらず、ブログはまさかのゼロ。なので、あとづけになりますが、インプットの1年だったのだと思います。そうします。
外部登壇
[DevLoveX] 大企業アジャイルの勘所 #devlovex
テーマ感として「自分の頭で考える」ことが大事だと伝えたかったスライドになります。制約の限りなくない世界ではなく、我々が日々対峙している現実世界の現場において、どうやっていくかを自分の中で暗黙化してしまっていることを言語化してみました。
[Developers Summit 2019 Summer] 大規模レガシー環境に立ち向かう有機的な開発フォーメーション #devsumi
コミュニティ活動
ことしも、デブサミ2020コンテンツ委員として活動させていただいております。なお、2020年の2月のデブサミも登壇予定です。 event.shoeisha.jp
印象に残った本
本は好きなのでいろんな本を読んでいます。たいてい流し読みで瞬間的に読み終えます。そんな中で印象に残った本は以下。
技術の創造と設計
心理学経営
買ってよかったもの
スカフコントローラー
FPSをやったりしているときに、親指を右スティックに載せたまま、○や✗ボタンを押したいシーンが発生。そのときに、親指を右スティックから離して○ボタンに指を移す間にキルされることが結構あり、その1秒程度の空白の時間をどうしても埋めたくなり背面にボタン(親指以外のボタンで押下可能になる)があるスカフを購入。最高。次はAstroのC40がほしい。 scufgaming.com
ダイニングテーブル(PC机用)
ダイニングテーブルをPC机用に購入。カフェ感のある木目そのままな感じのテイストで意識高いPCデスクにぴったり。この「かなでもの」おすすめ。 kanademono.design
SONY ワイヤレス ノイキャン イヤホン
もともとBOSEユーザーでヘッドフォンやイヤフォンはすべてBOSEだったのだけど、ノイズキャンセルのワイヤレスイヤホンがまずはソニーが出してきたので試しに購入。これはこれで良かった。(その2ヶ月後くらい?にAppleがAirpod proだしてしまい、それが未だに買えずじまい)。2020年はBOSEも同様のワイヤレスノイキャンイアホンだすぽいので、それに期待。 www.sony.jp
Razer Blade Pro
RazerのゲーミングノートPC。FF14等のゲームをPC環境で行いたく購入。デスクトップのBTOとかが最もコスパがよいと思うが、どちらかというと見た目と軽さとリビングにおける景観を意識しこれに。エアフローとかそういうのは無視。ゲーミングPC特有のへんな蛍光色に光るアレが我が家のリビングの景観を損ねるとのことでNGが出ておりもっともシンプルなRazerに。 www2.razer.com
ゲーム
仕事が忙しくなればなるほど、また、抱える課題や悩みが深く、複雑になればなるほど、家では仕事のことを1ミリも考えない時間として過ごすのがすごく重要に感じるようになってきました。その点、ゲームはやりだすと夢中になり仕事のことは一切考える余地がなくなるので、ゲームをしている時間は自分のMPを回復する上での必要不可欠な時間としています。
League of Legends
今更だけど、今更はまりました。会社のひとたちとやってます。世界大会が10月にあり、Discordでボイスチャットつなぎながら世界大会を観戦したりと楽しかったです。e-sports最高。 jp.leagueoflegends.com
Monster Hunter World Iceborn
マスターランク276、ハンターランク604。MHWからの合計で1200時間溶かした模様。 www.capcom.co.jp
Death Stranding
デススト。荷物を届けるだけのゲームなのだけど、最高に楽しかった。同じ届け先や同じ経路をN回通るため、どうしても効率化したくなり、効率化作業が生まれ、ひたすら効率化に時間を溶かすゲーム。ただし、本来の目的はストーリーをクリアすることであり、それだけを純粋にこなすのであれば30時間あればおわるものの、今後発生するN回のお届け作業を見越したオーバーエンジニアリングな自動化作業により、なぜかプレイ時間が100時間を超えるという本末転倒は手段の目的化。ただ、手段の目的化こそが指向であり、そのたかがHOWを突き詰めていくところがこのゲームの神槌であり、面白いところでもありました。 www.playstation.com
Dead by Daylight
去年から引き続き楽しい。会社のひとたちとやるとなお楽しい。鬼ごっこゲー。 www.jp.playstation.com
ファイアーエムブレム 風花雪月
2018年振り返り
2018年みなさま大変お世話になりました。2018年は、マネジメントする組織のメンバ数が20人から100人へと拡大したことがあり、はじめてずくしの1年でした。そのため、基本的にはインプットの年で、社外登壇やアウトプット活動はほとんどしておりません。そんなのする暇がなかった・・・・。でも、ゲームはかなりしました。ゲームの話と、数少ないアウトプットをまとめておきます。
Regional Scrum Gathering Tokyo 2018
Panel - 実感駆動でものづくり ー 協調学習過程としてのスクラム。欲しいものを、どうやって知るか。
川口さんから恐怖のパネルセッションのオファーを頂き、前回のPO祭りの当日丸投げ対策として事前に仕込んだ資料になります。
confengine.com
DevLove関西
”効率が良い”を考えてみる〜フロー効率性とリソース効率性のお話〜
大阪いきたいなー、なんか話すので。
— Itsuki KURODA (@i2key) 2018年4月27日
と言ったら、@daiksyさんと @yohhatu さんが以下のイベントを企画してくださり、大阪にたこ焼きたべにいきました。 devlove-kansai.doorkeeper.jp
書籍
日経システムズ6月号
「ここだけアジャイル」という特集に掲載いただきました。
日経システムズ7月号
「テスト特集」に掲載いただきました。
ブログ
今年はブログをまさかの2本しか書いていないのですが、両方とも普段からメンバーと1on1で話しているようなことで、それをそのままブログにするとはてブ数がそこそこつくのが意外でした。こういう話を日々、@Poohsunny とよくしています。
「再発防止策はチェックリストによる目視確認」から考えるアウトカムフォーカス
システム障害の対応から個別の対策ではなくどう組織知として還元していくかを考えたときに、この手のものは汎化して教訓化すると一気にスケーラブルになるので、そういうふうに捉えて振り返りをしています。同時に、それをパターンとして自分の引き出しとしています。 i2key.hateblo.jp
組織に流れるフォースを間接的にコントロールする仕事
フォースという単語からはてなブックマークのコメントにスターウォーズ感がすごく出てるのですが、イメージでいうとパターンランゲージの文脈におけるフォースを意図していました。日本語に置き換えると、コンテキスト上に流れるニーズや力なのですが汎化させると傾向と言うとすんなり入るかもしれません。 i2key.hateblo.jp
コミュニティ活動
デベロッパーズサミット 2018と2019のコンテンツ委員をやりました(2019は継続中)。
ゲーム
今年の個人的にベストゲームオブザイヤーは圧倒的にDead by Daylightでした。基本的にはホラーゲームのカテゴリで、殺人鬼(1人)とサバイバー(4人)で鬼ごっこして、脱出するゲームになります。鬼ごっこ&缶蹴り&けいどろ(どろけい)の悪魔合体のようなルールなので、幼少期にみながやったリアルな遊びをオンラインでやっているイメージです。なので、つまらないわけがない。 store.playstation.com これを、会社で部活化し、みんなでやっております。DeadbyDaylight部、部長の @yuriettys がブログを書いてくれているのでそっちもどうぞ。 yresy.hatenablog.com
年明けはずっと家でDead by Daylightやってる予定です。
ボクササイズ
会社のひとたちとb-monsterというボクササイズに通い出しました。2018年2月から開始して、未だに続いています。45分間ノンストップでのボクササイズは脳内がスッキリするし、汗びっしょりだし、結構いろいろな考え事できるし自分のルーチーンになりました。
金曜夜に意識高いサラリーマンした pic.twitter.com/D01ZTk3iMs
— Itsuki KURODA (@i2key) 2018年2月2日
旅
ドイツ行った
お城の様子です pic.twitter.com/bwIjGJiKnK
— Itsuki KURODA (@i2key) 2018年8月27日
クロアチア行った
クロアチアの様子です。 pic.twitter.com/3poENb2rE1
— Itsuki KURODA (@i2key) 2018年8月29日
トルコ行った
トルコの様子です pic.twitter.com/KsREHLyJ5x
— Itsuki KURODA (@i2key) 2018年9月1日
タイ行った(今)
プライベートプールで読書する様子です pic.twitter.com/7tsESnEXXg
— Itsuki KURODA (@i2key) 2018年12月29日
海外カンファレンス
Agile 2018
去年に引き続きAgile2018に参加しました。新しい発見というよりは、自分の中での経験を抽象化して定着をはかるための場としてとても有用でした。